Six Local Models, Six Behaviours: Lessons from Building Jeeves
I built a local AI agent playground for Ollama and ran the same prompts through Qwen, Phi4, Mistral, Llama, Gemma and DeepSeek. "Tool calling" turned out to be six different things wearing the same name — and the lessons learned along the way were the most fun part.
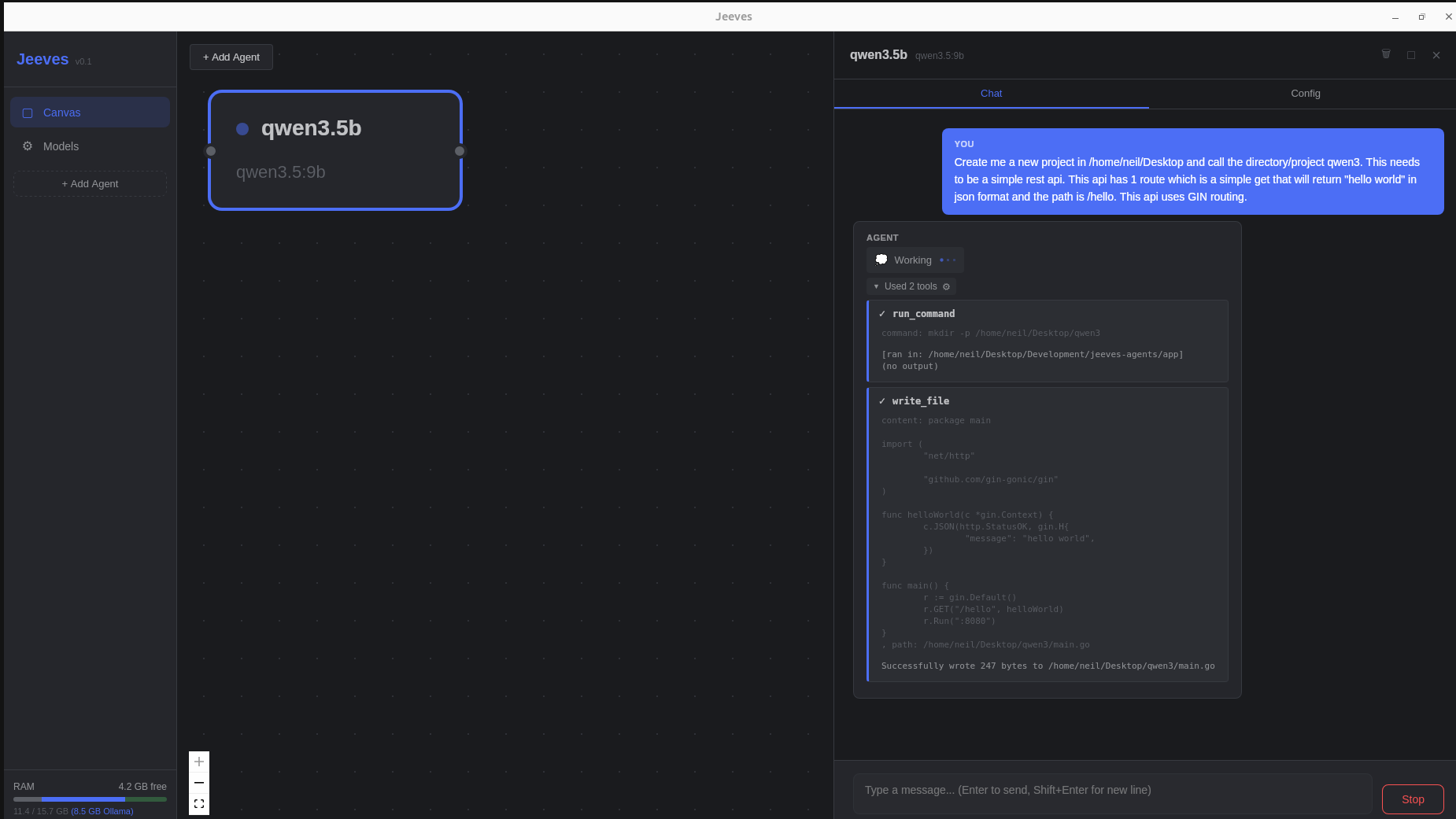
There's a moment when you're building anything with local AI models where you realise the documentation, the marketing copy, and the actual behaviour all live in different universes. I spent a few weeks building a desktop app called Jeeves — a playground for spinning up AI agents that run shell commands, edit files, and scaffold whole projects on my machine, all against locally-hosted Ollama models. Same agent loop, six different model families, six wildly different lived experiences.
The bit that surprised me most: "tool calling" is not one thing. It's six different things wearing the same name.
Why I Built It
Jeeves started as a way to actually use local models for real work — not just chat. The promise of running an agent that can read your files, run your tests, build your projects, all without anything leaving your laptop, is genuinely compelling. Privacy matters. Cost matters. And honestly, the engineering challenge of making any of it reliable matters too.
The architecture is straightforward: Go backend talking to Ollama's REST API, React frontend in a Wails desktop wrapper. Agents have permissions (read paths, write paths, exec, network), and a tool execution layer that runs the model's tool calls inside those bounds. Send a prompt, the model decides which tool to call, the backend executes it, returns the result, repeat. Standard agent loop.
The loop is simple. The models are not.
Tool Calling Is Not Solved
The standard for tool calling is supposed to be Ollama's native tool_calls field. You declare your tools in the chat request; the model returns its choice in a structured field; you execute it. Clean.
In practice, only some models actually use it. The rest output the same thing as text in their response. That's two completely different code paths to handle — structured field parsing, and "read the response text and try to figure out if it's a tool call."
Six Families, Six Wrappers
Each model family wraps text-mode tool calls differently:
- Qwen uses
<tool_call>...</tool_call>tags when it falls back from native - Mistral uses
[TOOL_CALLS]...[/TOOL_CALLS]markers - Phi4 prefixes with
functools[...] - Llama 3.2 emits Python-style function syntax —
[read_file(path='/foo')] - Gemma has its own
call:func_name{...}format - DeepSeek wraps in DSML tags
To support them all I ended up writing a fallback parser that tries each format in order, with a generic JSON scanner at the end. About 400 lines of Go, and most of that handles edge cases I'd never have anticipated.
The Malformed JSON Parade
The bigger surprise was that the JSON itself is often malformed:
- Models sometimes use backticks instead of double quotes for multi-line values, especially when writing file content
- They sometimes forget to escape inner quotes — picture a content field containing
import "fmt"where the inner double quotes aren't escaped — which technically terminates the JSON string halfway through - They sometimes emit literal newline characters inside string values instead of
\nescape sequences, which Go'sjson.Unmarshalrejects outright
So the parser needs more than format detection — it needs a repair pipeline. Mine does three passes: convert backtick strings to properly escaped JSON strings, find unescaped inner quotes and escape them using a heuristic based on what character follows the suspect quote, then replace literal control characters with their proper escape sequences. After the repair pipeline, the parse rate goes from "frequently broken" to roughly 95%.
Same Prompt, Different Paths
Beyond parsing, the number and quality of tool calls per task varies wildly between models. The same prompt — "create a Go REST API project with one /hello endpoint" — produces very different traces depending on which model you point it at:
- Qwen 3.5 (9b): around 8 tool calls, clean trajectory, scaffolds the directory, writes
main.goandgo.mod, runsgo build, starts the binary, hands back a working API. - Phi4: strong code generation per call, but slightly more verbose with intermediate verification steps.
- Llama 3.2 (3b): efficient for small tasks but tends to skip validation. Frequently calls itself "done" before it actually is.
- DeepSeek-coder: methodical to a fault — lots of read/list calls before each write. Reliable but slow.
- Mistral / Gemma: capable but more prone to drift into the wrong format mid-conversation.
There's no clear winner; just different temperaments. Bigger Qwen models felt the most reliable overall. Phi4 had the strongest code per call. Llama 3.2 was the cheapest to run but the easiest to lose. Picking the right model for the task turned out to matter more than I'd expected.
The Drift Problem
Then there's drift. Same prompt, two runs apart, completely different approach. And in some cases the model gets stuck in loops that the standard agent loop can't break out of.
My favourite drift pattern: a model is told to verify a server. It starts the server in the background with &, then immediately kills it with pkill -f. Then it thinks "oh wait, I haven't verified" and starts it again. Then kills it. Then starts it. Then kills it. Forever.
I fixed that with two changes. First, I told the model in the system prompt that the 30-second command timeout is the success signal for server verification — just run the server in the foreground, let it time out, done. Second, an oscillation detector in my own code that catches when the model is alternating between the same two commands and injects a system message telling it to stop. Crude but effective. It's the harness asking the model to think more carefully, which feels like cheating until you remember the alternative is "infinite loop".
What I'd Take Away
For anyone else building agent layers against local models:
- Native tool calling support is the single biggest differentiator. If your target model supports it cleanly, your life is dramatically simpler. If it doesn't, build the fallback parser early.
- Test with multiple models even if you plan to standardise on one. The behavioural differences are too big to discover late.
- Build the repair pipeline. Even native-tool models occasionally emit a tool call as text, and that JSON is usually malformed in some small way.
- Prompt design matters more for smaller models, but cleaner prompts work better across the board. Most of my prompt rules ended up shorter over time, not longer. A model trying to obey ten rules ends up obeying none of them.
- Treat the timeout as a signal, not a failure. Once I stopped fighting the 30-second command timeout and started using it as the success criterion for long-running processes, a whole class of loops disappeared.
Closing Thought
The fun is real. This is a genuinely interesting corner of programming to work in right now. Watching a 9b parameter model running entirely on a laptop scaffold and run a working REST API in a couple of minutes is a glimpse of where this is headed — local, capable, private. The roughness is what makes it fun. Every "this should work" failure becomes a small puzzle. Every model that does something unexpected teaches you something about how it actually thinks.
Jeeves is open source on GitHub. The code is a snapshot of a fast-moving target, but the patterns will probably hold up for a while yet.